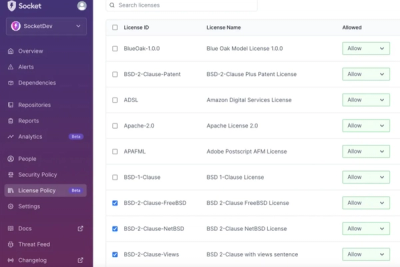
Product
Introducing License Enforcement in Socket
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
By Philipp Burckhardt - Oct 17, 2024
The strtok3 npm package is a streaming tokenizer for Buffer and string inputs in Node.js. It allows developers to parse through binary data or strings efficiently by defining tokenizers that can extract pieces of data sequentially. This is particularly useful for reading binary files or network streams where data structures are defined in terms of sequences or patterns of bytes.
Tokenizing fixed-length binary data
This feature allows for reading fixed-length binary data from a file. The example demonstrates reading a 32-bit unsigned integer from the beginning of a file.
const strtok3 = require('strtok3');
const { token } = require('strtok3/core');
async function parseBinaryFile(filePath) {
const tokenizer = await strtok3.fromFile(filePath);
const header = await tokenizer.readToken(token.UINT32_LE);
console.log('Header:', header);
}Tokenizing a stream of data
This feature is used for tokenizing data directly from a stream. The example shows how to read a size as a 32-bit unsigned integer and then read a buffer of that size from the stream.
const strtok3 = require('strtok3');
const { token } = require('strtok3/core');
const fs = require('fs');
const stream = fs.createReadStream('path/to/file');
const tokenizer = strtok3.fromStream(stream);
async function readData() {
const size = await tokenizer.readToken(token.UINT32_LE);
const data = await tokenizer.readToken(new token.BufferType(size));
console.log('Data:', data.toString());
}binary-parser is a package for building efficient binary data parsers. It is similar to strtok3 in that it helps parse binary data, but it uses a declarative approach to define the structure of the binary data instead of the imperative approach used by strtok3.
![]()
![]()
![]()

![]()
![]()
A promise based streaming tokenizer for Node.js and browsers. This node module is a successor of strtok2.
The strtok3 contains a few methods to turn different input into a tokenizer. Designed to
It can read from:
npm install strtok3
Module: version 7 migrated from CommonJS to pure ECMAScript Module (ESM). JavaScript is compliant with ECMAScript 2019 (ES10). Requires Node.js ≥ 16 engine.
Use one of the methods to instantiate an abstract tokenizer:
All of the strtok3 methods return a tokenizer, either directly or via a promise.
strtok3.fromFile()| Parameter | Type | Description |
|---|---|---|
| path | Path to file (string) | Path to file to read from |
Note: that file-information is automatically added.
Returns, via a promise, a tokenizer which can be used to parse a file.
import * as strtok3 from 'strtok3';
import * as Token from 'token-types';
(async () => {
const tokenizer = await strtok3.fromFile("somefile.bin");
try {
const myNumber = await tokenizer.readToken(Token.UINT8);
console.log(`My number: ${myNumber}`);
} finally {
tokenizer.close(); // Close the file
}
})();
strtok3.fromStream()Create tokenizer from a Node.js readable stream.
| Parameter | Optional | Type | Description |
|---|---|---|---|
| stream | no | Readable | Stream to read from |
| fileInfo | yes | IFileInfo | Provide file information |
Returns a Promise providing a tokenizer.
strtok3.fromWebStream()Create tokenizer from a WHATWG ReadableStream.
| Parameter | Optional | Type | Description |
|---|---|---|---|
| readableStream | no | ReadableStream | WHATWG ReadableStream to read from |
| fileInfo | yes | IFileInfo | Provide file information |
Returns a Promise providing a tokenizer
import strtok3 from 'strtok3';
import * as Token from 'token-types';
strtok3.fromWebStream(readableStream).then(tokenizer => {
return tokenizer.readToken(Token.UINT8).then(myUint8Number => {
console.log(`My number: ${myUint8Number}`);
});
});
strtok3.fromBuffer()| Parameter | Optional | Type | Description |
|---|---|---|---|
| uint8Array | no | Uint8Array | Uint8Array or Buffer to read from |
| fileInfo | yes | IFileInfo | Provide file information |
Returns a Promise providing a tokenizer.
import * as strtok3 from 'strtok3';
const tokenizer = strtok3.fromBuffer(buffer);
tokenizer.readToken(Token.UINT8).then(myUint8Number => {
console.log(`My number: ${myUint8Number}`);
});
The tokenizer allows us to read or peek from the tokenizer-stream. The tokenizer-stream is an abstraction of a stream, file or Uint8Array. It can also be translated in chunked reads, as done in @tokenizer/http;
What is the difference with Nodejs.js stream?
tokenizer.ignore()The tokenizer.position keeps tracks of the read position.
tokenizer.fileInfoOptional attribute describing the file information, see IFileInfo
tokenizer.positionPointer to the current position in the tokenizer stream. If a position is provided to a read or peek method, is should be, at least, equal or greater than this value.
There are two kind of methods:
tokenizer.readBuffer()Read buffer from stream.
readBuffer(buffer, options?)
| Parameter | Type | Description |
|---|---|---|
| buffer | Buffer | Uint8Array | Target buffer to write the data read to |
| options | IReadChunkOptions | An integer specifying the number of bytes to read |
Return value Promise<number> Promise with number of bytes read. The number of bytes read maybe if less, mayBeLess flag was set.
tokenizer.peekBuffer()Peek (read ahead) buffer from tokenizer
peekBuffer(buffer, options?)
| Parameter | Type | Description |
|---|---|---|
| buffer | Buffer | Uint8Array | Target buffer to write the data read (peeked) to. |
| options | IReadChunkOptions | An integer specifying the number of bytes to read. |
Return value Promise<number> Promise with number of bytes read. The number of bytes read maybe if less, mayBeLess flag was set.
tokenizer.readToken()Read a token from the tokenizer-stream.
readToken(token, position?)
| Parameter | Type | Description |
|---|---|---|
| token | IGetToken | Token to read from the tokenizer-stream. |
| position? | number | Offset where to begin reading within the file. If position is null, data will be read from the current file position. |
Return value Promise<number>. Promise with number of bytes read. The number of bytes read maybe if less, mayBeLess flag was set.
tokenizer.peekToken()Peek a token from the tokenizer.
peekToken(token, position?)
| Parameter | Type | Description |
|---|---|---|
| token | IGetToken | Token to read from the tokenizer-stream. |
| position? | number | Offset where to begin reading within the file. If position is null, data will be read from the current file position. |
Return value Promise<T> Promise with token value peeked from the tokenizer.
tokenizer.readNumber()Peek a numeric token from the tokenizer.
readNumber(token)
| Parameter | Type | Description |
|---|---|---|
| token | IGetToken | Numeric token to read from the tokenizer-stream. |
Return value Promise<number> Promise with number peeked from the tokenizer-stream.
tokenizer.ignore()Advance the offset pointer with the number of bytes provided.
ignore(length)
| Parameter | Type | Description |
|---|---|---|
| ignore | number | Numeric of bytes to ignore. Will advance the tokenizer.position |
Return value Promise<number> Promise with number peeked from the tokenizer-stream.
tokenizer.close()Clean up resources, such as closing a file pointer if applicable.
Each attribute is optional:
| Attribute | Type | Description |
|---|---|---|
| offset | number | The offset in the buffer to start writing at; if not provided, start at 0 |
| length | number | Requested number of bytes to read. |
| position | number | Position where to peek from the file. If position is null, data will be read from the current file position. Position may not be less then tokenizer.position |
| mayBeLess | boolean | If and only if set, will not throw an EOF error if less then the requested mayBeLess could be read. |
Example:
tokenizer.peekBuffer(buffer, {mayBeLess: true});
File information interface which describes the underlying file, each attribute is optional.
| Attribute | Type | Description |
|---|---|---|
| size | number | File size in bytes |
| mimeType | number | MIME-type of file. |
| path | number | File path |
| url | boolean | File URL |
The token is basically a description what to read form the tokenizer-stream. A basic set of token types can be found here: token-types.
A token is something which implements the following interface:
export interface IGetToken<T> {
/**
* Length in bytes of encoded value
*/
len: number;
/**
* Decode value from buffer at offset
* @param buf Buffer to read the decoded value from
* @param off Decode offset
*/
get(buf: Uint8Array, off: number): T;
}
The tokenizer reads token.len bytes from the tokenizer-stream into a Buffer.
The token.get will be called with the Buffer. token.get is responsible for conversion from the buffer to the desired output type.
To exclude fs based dependencies, you can use a submodule-import from 'strtok3/lib/core'.
| function | 'strtok3' | 'strtok3/lib/core' |
|---|---|---|
parseBuffer | ✓ | ✓ |
parseStream | ✓ | ✓ |
fromFile | ✓ |
To convert a Web-API readable stream into a Node.js readable stream, you can use readable-web-to-node-stream to convert one in another.
Example submodule-import:
import * as strtok3core from 'strtok3/core'; // Submodule-import to prevent Node.js specific dependencies
import { ReadableWebToNodeStream } from 'readable-web-to-node-stream';
(async () => {
const response = await fetch(url);
const readableWebStream = response.body; // Web-API readable stream
const nodeStream = new ReadableWebToNodeStream(readableWebStream); // convert to Node.js readable stream
const tokenizer = strtok3core.fromStream(nodeStream); // And we now have tokenizer in a web environment
})();
(The MIT License)
Copyright (c) 2020 Borewit
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the 'Software'), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED 'AS IS', WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.
FAQs
A promise based streaming tokenizer
The npm package strtok3 receives a total of 4,004,869 weekly downloads. As such, strtok3 popularity was classified as popular.
We found that strtok3 demonstrated a healthy version release cadence and project activity because the last version was released less than a year ago. It has 0 open source maintainers collaborating on the project.
Did you know?

Socket for GitHub automatically highlights issues in each pull request and monitors the health of all your open source dependencies. Discover the contents of your packages and block harmful activity before you install or update your dependencies.
Product
Ensure open-source compliance with Socket’s License Enforcement Beta. Set up your License Policy and secure your software!
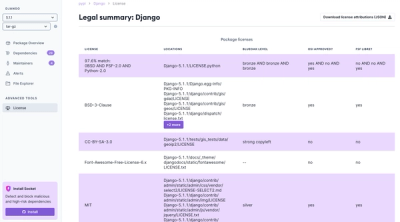
Product
We're launching a new set of license analysis and compliance features for analyzing, managing, and complying with licenses across a range of supported languages and ecosystems.
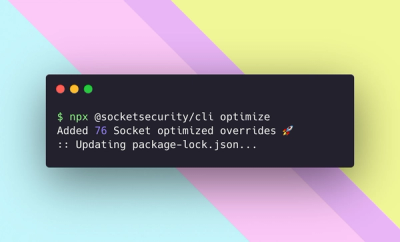
Product
We're excited to introduce Socket Optimize, a powerful CLI command to secure open source dependencies with tested, optimized package overrides.